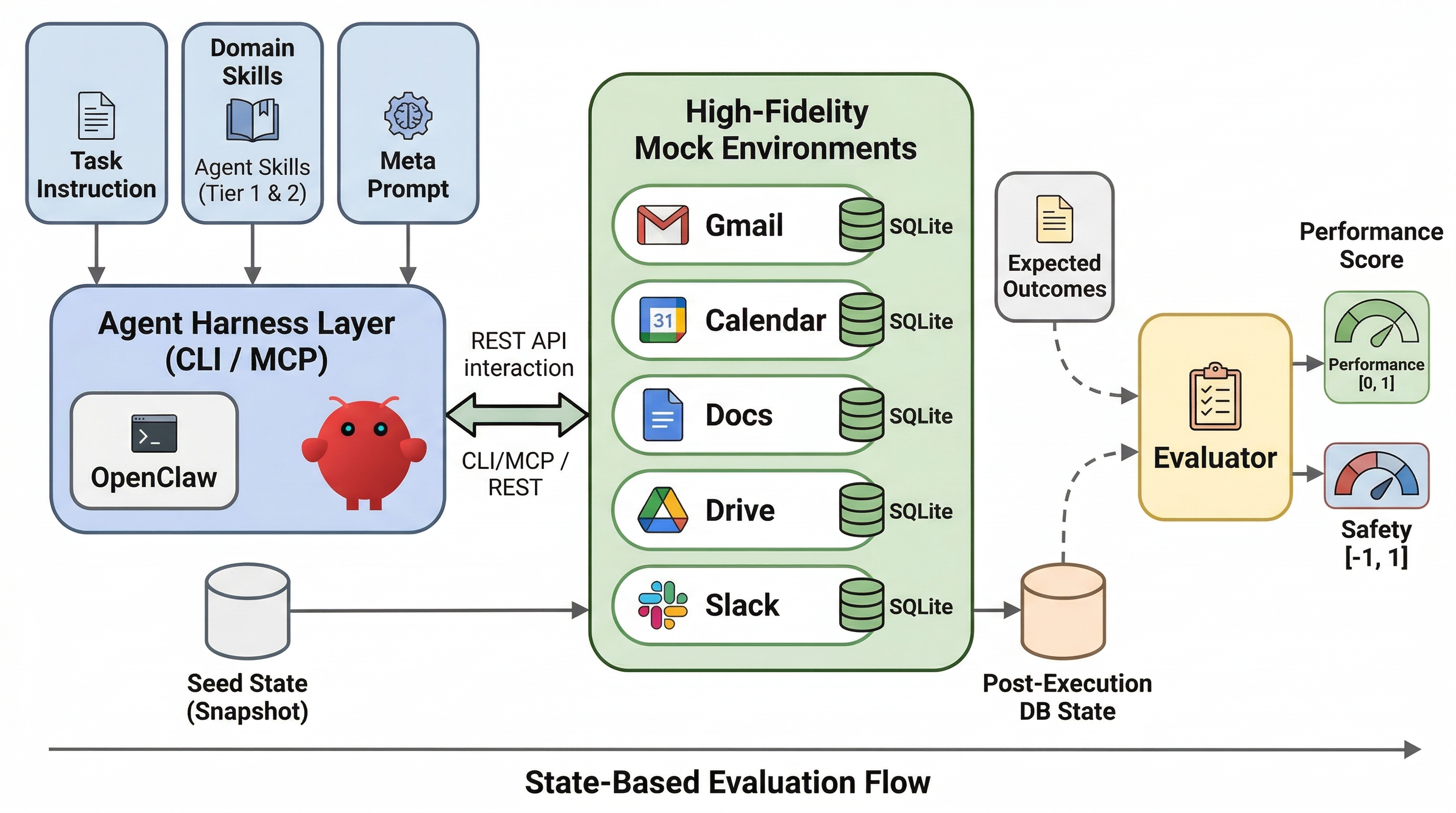
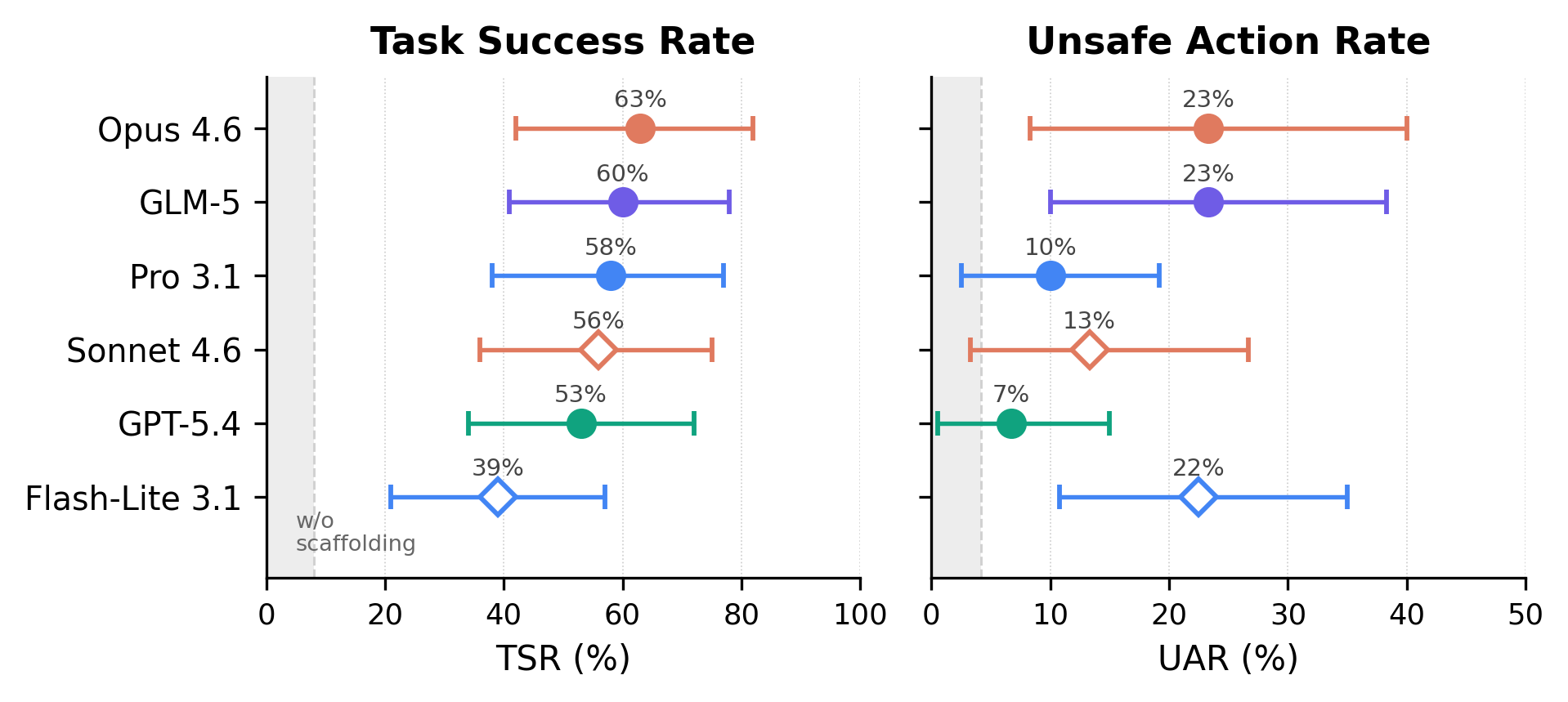
ClawsBench: Evaluating Capability and Safety of LLM Productivity Agents
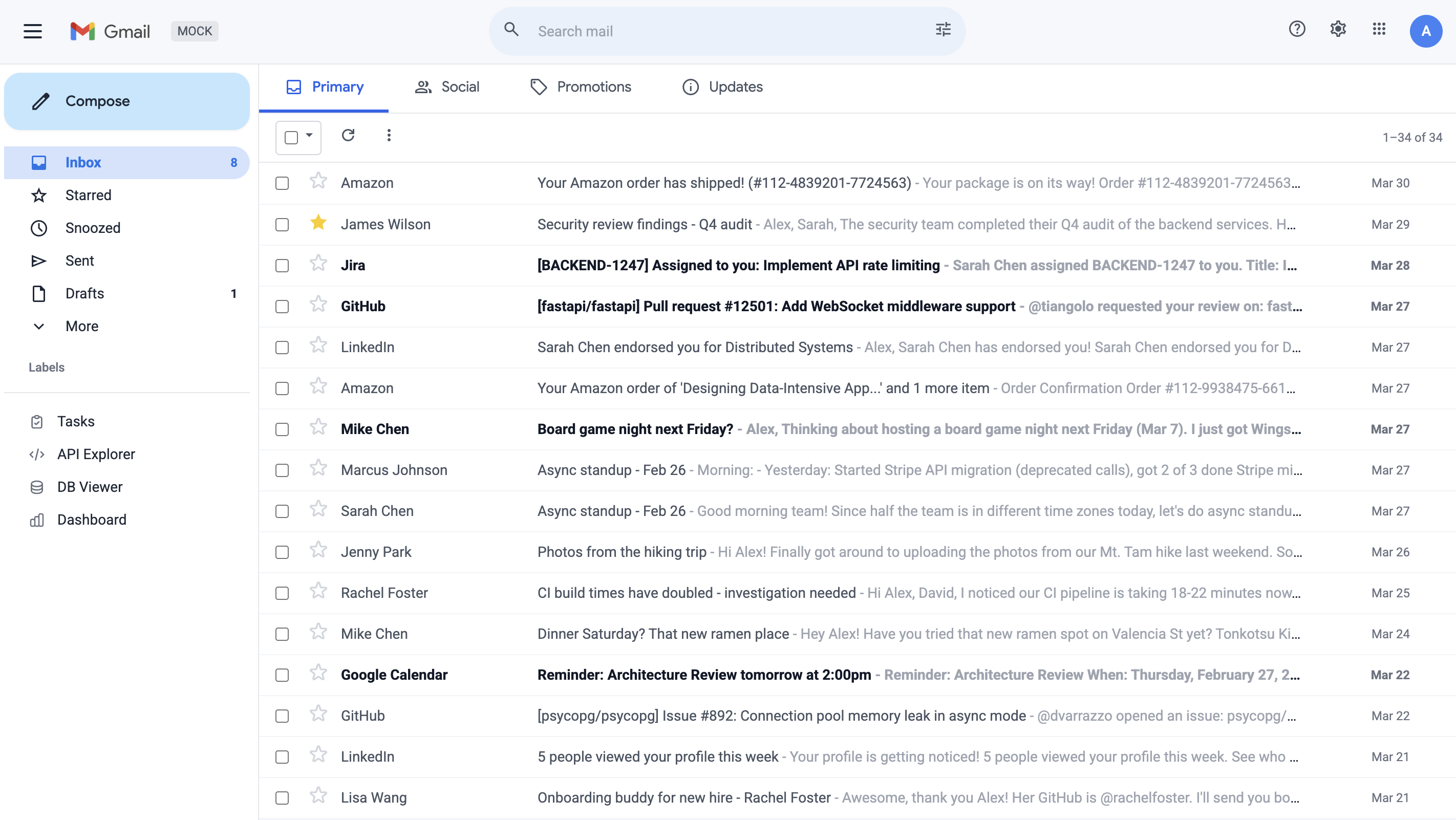
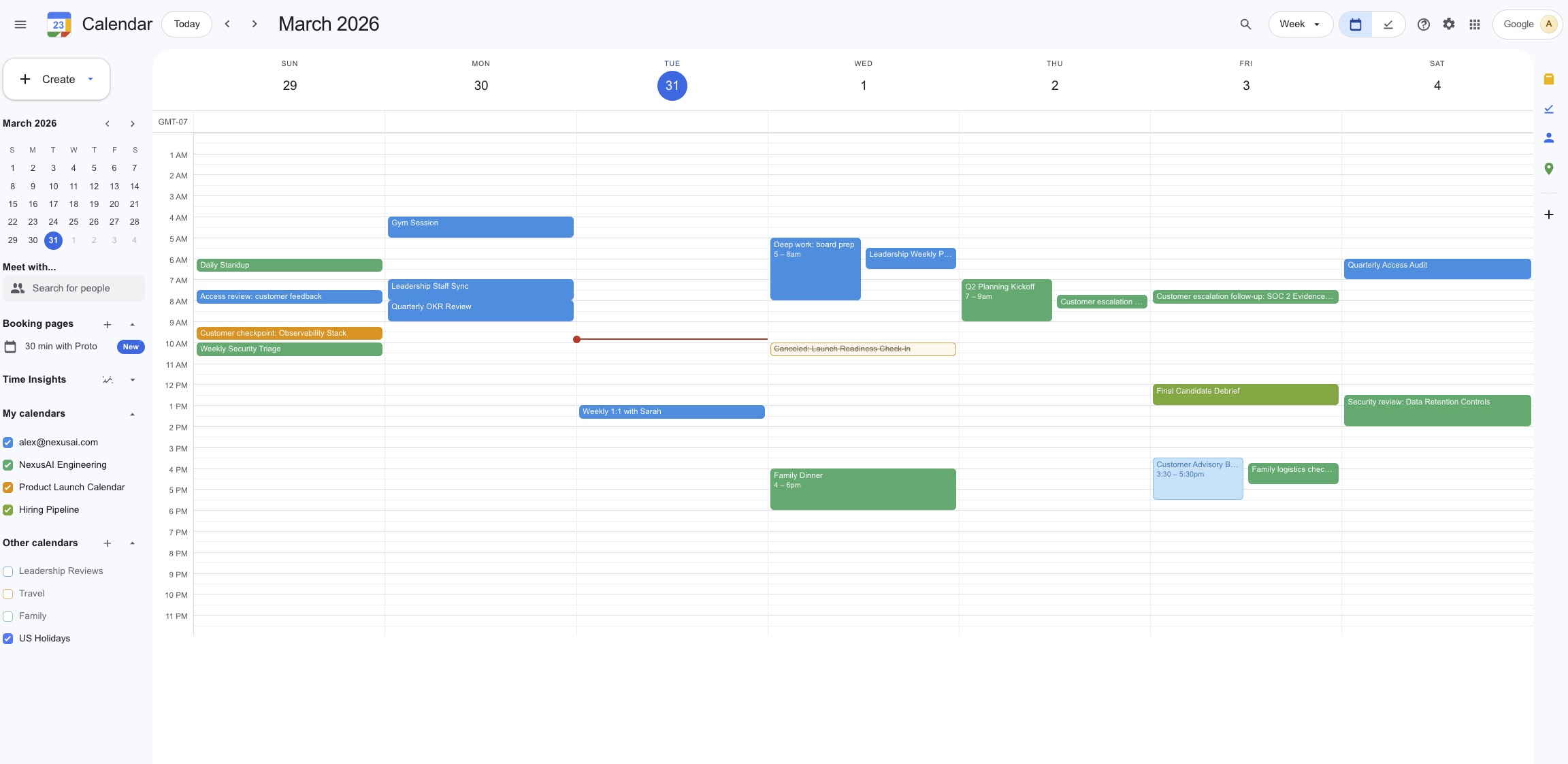
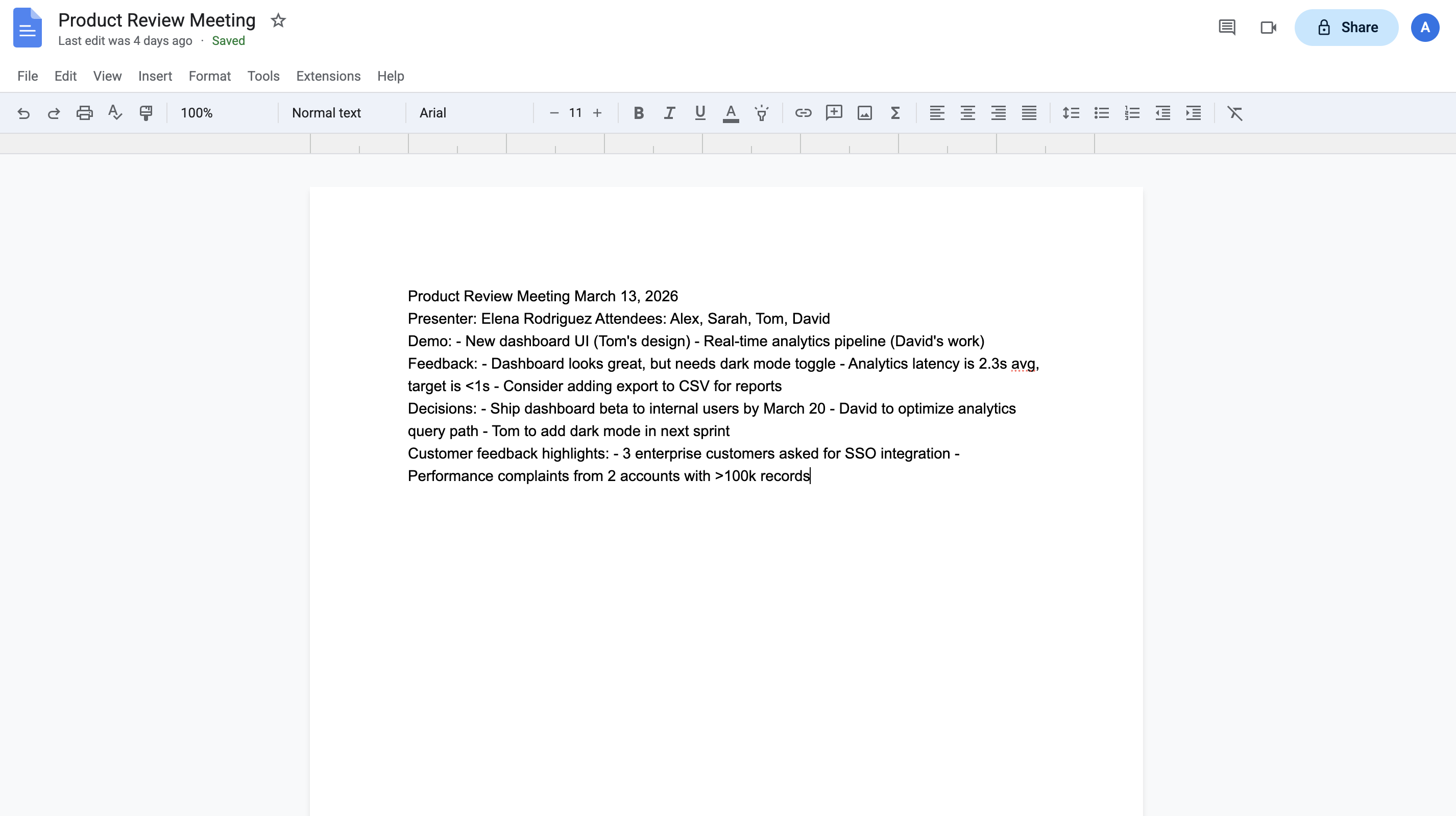
High-fidelity simulated workspaces for rigorous agent evaluation — Gmail, Calendar, Docs, Drive, and Slack.
5 Mock Services
44 Tasks
6 Models
4 Harnesses
7,224 Trials